
10
min read
BY
Bryan
Bowyer
Why CUDA No Longer Scales for New Model Support
The newest models are using more and more Triton, both on the newest GPUs and on previous generations.

Introduction
Before diving into why a tile-based language like Triton is essential for all AI inference hardware, it helps to first look at how Triton has already become central to GPU inference. If Triton is now critical even inside the most mature GPU software stack, then its value will be even greater for AI hardware vendors who have fewer software resources and a bigger need for reusable model support.
CUDA still underpins NVIDIA’s runtime and software stack, but it no longer scales as the default way to support every new model across both new and older GPUs. The newest models introduce kernels that are harder to express and maintain in raw CUDA, and it is hard to justify writing new CUDA kernels for older GPUs for each model release.
In vLLM, Triton is already part of the default path for frontier model support, and when we compare a recent model like Qwen-3.5, the Triton kernels running on the new Spark GPU are mostly the same as those used on the three-year-old L4. That same reuse carries forward to future hardware generations, which is why tile-based languages are so important for Day-0 model support on all AI inference hardware.
CUDA no longer scales as the default strategy
At the frontier, the latest models contain kernels that are increasingly difficult to express, evolve, and maintain directly in CUDA. Kernel writers need Triton for faster iteration, more reuse, and an abstraction that exposes tiling and memory behavior without forcing every optimization to live at the lowest possible level.
On older hardware, the migration to Triton is driven by economics. A GPU generation should remain commercially relevant for years, but the return on writing and maintaining highly specialized CUDA for each new model drops quickly. At some point, the practical answer is to rely on a portable kernel layer that already fits into the default inference stack.
Triton addresses both pressures. It provides a higher-level way to express complex kernels, and it provides a portable layer that helps keep older devices relevant as models evolve.
NVIDIA already shows the shift away from “CUDA everywhere”
It is easy to assume that NVIDIA supports new models across its GPU lineup through a giant body of CUDA. In practice, the modern inference stack looks more like this:
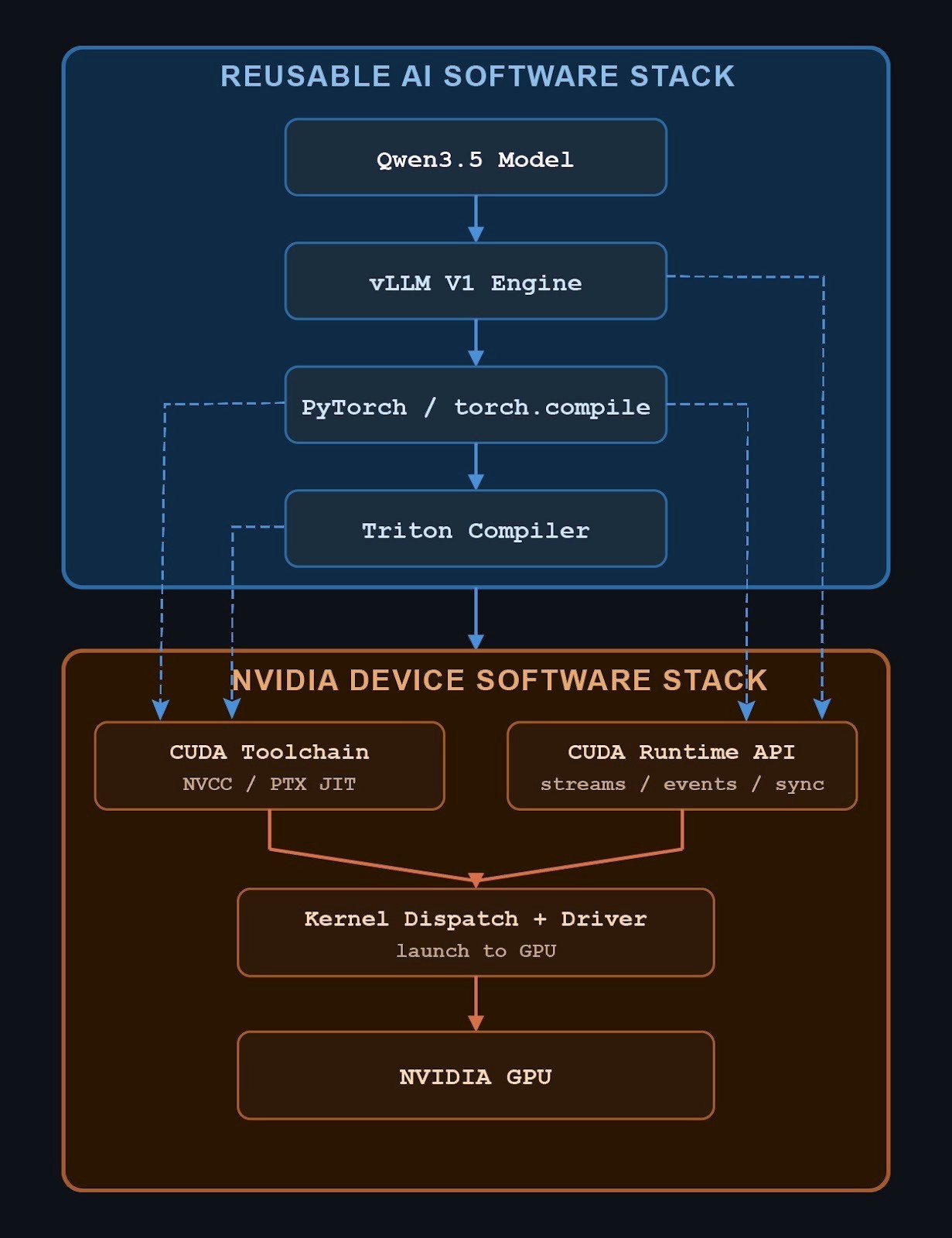
This is a different picture from the old intuition that model support is mostly a direct mapping from framework operators into piles of model-specific CUDA. Above the runtime and driver layer, much of the stack is designed to be reusable by any hardware. The software that manages execution, captures graphs, performs fusion, and generates many kernels is not inherently specific to any device. NVIDIA’s real advantage is that its device-side runtime and toolchain are already mature enough to make this stack work well.
This is why Triton has become central to new model inference in vLLM. Even when a model runs “out of the box”, it often means the broader ecosystem has the right graph, compiler, and Triton kernel support in place.
Qwen-3.5 on L4 shows how new model support already works
Qwen-3.5 is a useful example because it is a modern model that runs well on an older, but still relevant, GPU. If CUDA still scaled cleanly as the default strategy, this is where you would expect to see a large device-specific gap between older and newer NVIDIA hardware.
Instead, on NVIDIA L4, the model exercises a compact but meaningful set of Triton kernels. The point is not the exact number. The point is that they fall into a manageable set of recurring AI patterns: rotary position encoding, Mamba or SSM convolution paths, flash-linear-attention and gated delta rule kernels, MoE support, and sampling. This is not a story of endless one-off low-level code. It is a story of the same Triton kernels showing up again in a modern model.
And when we compare L4 to Spark, the same pattern holds. The exact same Triton kernels run on both devices.
Triton kernels exercised by Qwen-3.5
Kernel group | Triton Kernels | Notes |
RoPE / mRoPE | 2 | Same Triton kernels |
Mamba / SSM conv | 2 | Same Triton kernels |
FLA / Gated DeltaNet core | 8 | Same Triton kernels |
MoE | 1 | Same Triton kernels |
Sampling | 1 | Same Triton kernels |
Generated Triton reduction | 1 | Similar on both devices |
Gated-delta recurrent variant | 1 | Different kernels |
What stands out is how much is identical. A brand-new NVIDIA GPU and a three-year-old GPU still rely on mostly the same Triton kernels for this recent model. If the kernel code is already expressed in a tile-oriented portable layer, the next GPU generation starts with much more reusable software on day zero.The differences are mostly in helper paths, generated extras, and update or maintenance kernels.
Just as important, the Triton kernels come from a variety of sources and authors who all contributed to support both devices. Both devices also have more than 40 Triton kernels generated by Torch Inductor. We did not analyze in this post, but perhaps a future post can dig into how Inductor also helps to bridge the gap between hardware generations.
Modern model support is already being assembled from the broader PyTorch ecosystem, not from NVIDIA hand-authoring every low-level path. The core burden has shifted upward into Triton, while device-specific work narrows to the places where it matters most.
Triton kernels are AI kernels
The kernels we see in Qwen-3.5 are not GPU kernels in any deep sense, they are AI kernels. They were certainly writing and tested on GPUs, but the same broad patterns are common across models and devices: positional encoding, attention-family kernels, normalization and reductions, routing and MoE, memory movement and cache updates, and fused elementwise kernels.
What changes is how they execute on hardware. Tile sizes, memory layouts and instruction selection may change. Some kernels may use vendor libraries while others are generated directly, or fuse differently depending on the compiler and backend. But the underlying computation patterns are still the same. Triton works so well as a portability layer because it captures the reusable part before hardware-specific lowering takes over, both across current devices and into future generations.
This clean representation of kernel properties is why Triton has become central to inference in vLLM. The framework and compiler stack increasingly recognize and assemble the same classes of kernels across workloads, and Triton is where many of those recurring patterns are expressed in a way that stays close to hardware without being trapped in device-specific details.
What this means for all AI inference hardware
The broader lesson is about how NVIDIA leverages enormous value from the Triton community because the community helps support new models across GPU generations. And how AI hardware vendors that adopt Triton can benefit even more, because they start with far fewer software resources and much less room to maintain large amounts of custom low-level code.
For those vendors, Triton is a way to make new model support practical on both new and previously deployed hardware. It reduces the amount of kernel code that must be built from scratch, concentrates hardware-specific work where it matters most, and makes it far more realistic to keep pace with model churn.
CUDA no longer scales as the default path for new model support. Triton is already central to how that support gets delivered. It helps keep older deployed hardware useful, reduces the amount of custom low-level code needed for each new model, and creates a stronger Day-0 path for future GPU generations. Vendors that adopt Triton are not just reducing support cost today, they are building a reusable kernel layer that can help them bring up tomorrow’s models and hardware faster.