
We bring Triton to your chips
A Platform for AI Inference Beyond GPUs
A wave of NPU hardware specialized for LLM inference is challenging GPUs. We are building a platform based on the Triton language and compiler that will work across all of them.
Triton is foundational for LLMs, combining accessibility and optimization critical for all inference hardware.
Model Innovation Starts with Triton
Triton is essential for rapid experimentation and iteration for new model concepts and research prototypes.
Compliments your Existing Software
Easily add Triton-generated kernels only where they are needed.
Integrate Optimized Kernels
Modern LLMs embed optimized Triton kernels for maximum inference performance and efficiency.
Specialized LLM Kernels
Projects from Liger Kernel to vLLM use Triton to create specialized kernels, maximizing LLM operation performance.
Accessible Parallelism
Triton's Python-like syntax simplifies parallel programming, enabling ML engineers to write efficient code without deep hardware expertise.
Hardware Agnostic Compiler
Triton is an open-source compiler that generates optimized machine code for diverse architectures, ensuring broad applicability and future-proofing.
How Triton Works

Triton generates kernels that integrate with your existing kernels or internal representations. Some models may not need any Triton.
Optimizing Kernels with Triton
Compilers struggle to optimize for all cases from one source kernel. This example shows how even a simple vector add on CPU can be more optimal than default PyTorch kernels. PyTorch will automatically use the Triton kernel when it is more optimal.
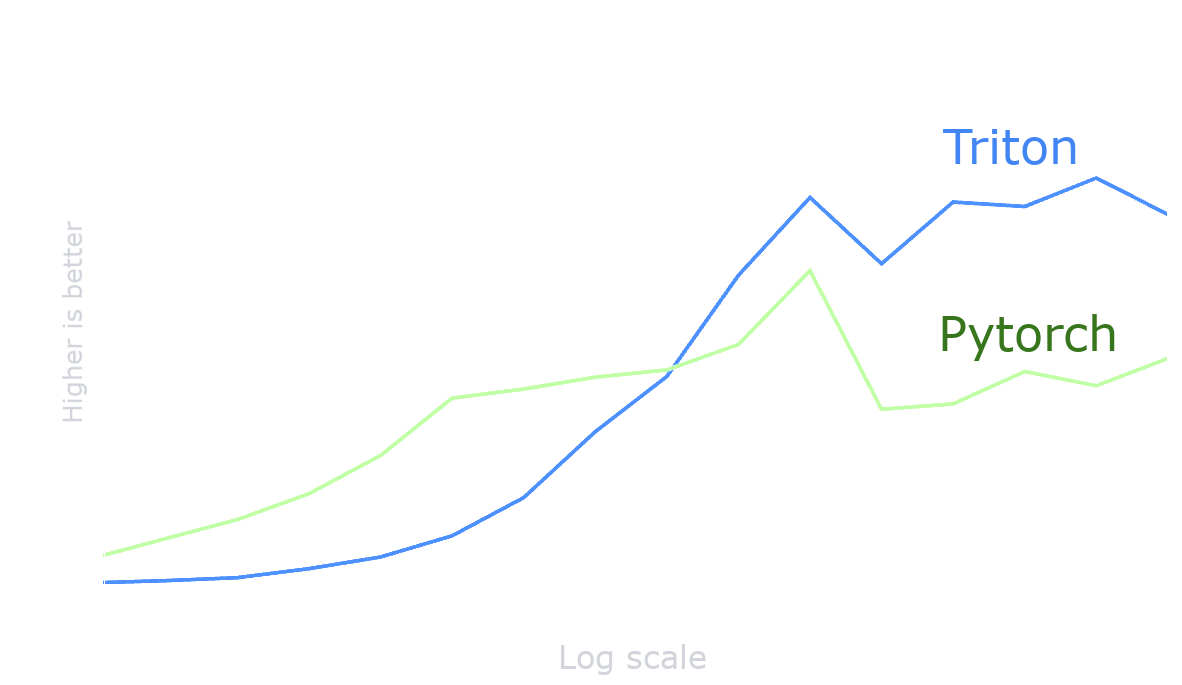
Why Kernelize?
Industry Standard
Open-source code built on industry standard AI infrastructure prevents lock-in and falling behind
Compiler Experts
Our team has decades of experience building compilers for GPU and NPU AI hardware
Triton Community
Leverage the biggest and most experienced AI compiler community in the world